해시테이블 (Hash Table)
해시테이블은 key와 value쌍을 가지는 비선형 자료구조이다.
파이썬의 dict(딕셔너리)도 해시테이블을 기반으로 구현되어있다.
이 자료형은 대규모의 데이터 셋에서도 빠른 검색을 제공하는데, 그럴 수 있는 이유가 무엇일까?
그 답은 해시테이블의 생성 원리를 뜯어보면 알 수 있다.
해시테이블 생성의 핵심은 "해시함수"이다. 해시함수는 입력된 key를 해시값으로 반환하고, 이 해시값은 배열에 접근하는 인덱스로 쓰이게 된다.
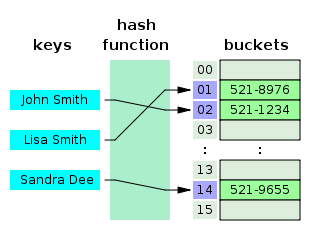
우리는 '배열'에 데이터를 저장하고 싶다. 하지만 배열은 인덱스(index)로만 접근이 가능한 자료형이다.
우리가 가진 데이터에서 배열접근에 사용될 key는 문자열(str)이므로, 우리는 이 문자열을 인덱스(int)로 바꿔주는 과정을 필수적으로 거쳐야 한다. 그리고 그 과정이 바로 해시함수를 통한 '해싱'이다.
이런 과정을 거치고 나야 우리는 해시함수가 생성한 해시값을 인덱스로 사용해서 배열에 접근할 수 있고, 데이터를 저장하고 검색할 수 있게 된다.
이때, 배열에서 실제 데이터가 저장되는 공간을 '버킷(bucket)'이라고 한다. 따라서 위 그림에서 'bucket들이 이어져있는 저 구조'가 "배열"이며, 곧 "해시테이블"이다.
해시테이블에서 빠른 검색이 가능한 이유는 해시함수가 동일한 key입력에 대해서 항상 동일한 해시값을 return해주기 때무이다. 따라서 우리는 key의 해시값만 알면 (이를 인덱스로 사용해서) 곧바로 배열에 접근할 수 있는 것이다. 해시테이블의 시간 복잡도는 O(1)로 빠른 편이다.
해시충돌 (Hash Collision)
해시충돌이란 해시함수가 서로 다른 key에 대해 동일한 해시값을 생성시킨 경우에 발생한다.
사실 해시함수의 입력값(key)는 무한한 반면 출력값(해시값)의 가짓수는 유한하므로 해시충돌은 필연적으로 발생할 수밖에 없다.
이는 '비둘기집 원리'를 통해서 알 수 있다.
즉, 9개의 공간이 있는 곳에 10개의 아이템이 들어오면 반드시 1번 이상은 충돌이 발생한다는 것이다.
해시충돌이 같은 해시값을 갖는 데이터가 생김을 의미하고, 이는 곧 특정 bucket에 데이터가 집중됨을 뜻한다. 만약 해다 ㅇbucket에 충분한 공간이 없다며 overflow가 발생할 수 있다. 이렇게 너무 많은 해시충돌은 해시테이블의 성능 저하를 초래할 수 있다.
해결방법
해시충돌을 해결하는 방법은 여러가지가 있지만, 대표적인 2가지는 다음과 같다.
해시충돌의 해결은 기본적으로 '같은 해시값을 가지더라도 저장공간을 추가로 만들거나/찾아주거나' 혹은 '중복되는 해시값 자체를 가지지 않게 교정'하는 것일 수밖에 없다.
1. Chaining
해시충돌이 발생하면 "연결리스트"로 데이터들을 연결하는 방식이다.

연결리스트는 메모리상에 연속적으로 존재하지 않고, "값"과 "포인터"만 가지는 것을 특징으로 하는 자료형이다.
따라서 해시테이블(배열)에서 특정 인덱스의 bucket공간이 부족하더라도 chain을 이어가듯 연결리스트로 해시값이 중복된 데이터들을 저장할 공간들을 새롭게 만들어낼 수 있다.
2. Open Addressing
앞선 Chaining의 경우에는 특정 인덱스의 bucket이 차더라도 그에 이어서 연결리스트를 이어붙이기 때문에 데이터의 주소값은 바뀌지 않는다. 하지만 Open Addressing은 해시충돌이 일어나면 아예 다른 bucket에 데이터를 저장하므로 데이터의 주소값 자체가 바뀐다.
1. 선형 탐사
: 해시충돌 시 순차적으로 (배열에서) 빈 버킷을 탐색하여 빈 데이터를 삽입함
2. 제곱 탐사
: 해시충돌 시 (배열에서) 제곱만큼 건너뛴 버킷을 탐색하고 비어있으면 데이터를 삽입함 (1,4,9,16...)
3. 이중 해시
: 해시충돌 시 다른 해시함수를 한번 더 적용한 결과를 이용함
그렇다면 이렇게 필연적인 해시충돌이 생김에도 불구하고, 우리는 왜 해시테이블을 사용하는 걸까?
그 답은 해시테이블을 사용하면 적은 리소스로 많은 데이터를 효율적으로 관리할 수 있기 때문이다.
무한에 가까운 key값을 유한한 해시값으로 매핑해서 관리하므로 우리는 작은 캐쉬메모리로도 많은 데이터를 효율적으로 사용할 수 있다.
또 key값을 변환한 해시값을 통해 배열에 접근하므로써 빠른 데이터 검색이 가능하고, 대규모 데이터 셋에 적합하다는 점도 우리가 해시테이블을 사용하는 이유일 것이다.
참고자료
'TIL' 카테고리의 다른 글
| [TIL 2024. 04. 01] SQLAlchemy | MySQL DB 테이블 생성 (0) | 2024.04.01 |
|---|---|
| [TIL 2024.03. 29] 퀵 정렬 (w. 시간 복잡도) (0) | 2024.03.29 |
| [TIL 2024. 03. 27] 모의고사 | zip() | 부분문자열 이어붙여 문자열 만들기 (0) | 2024.03.27 |
| [TIL 2024. 03. 26] 최소 직사각형 | 2차원 리스트에서 요소 추출하기 (0) | 2024.03.26 |
| [TIL 2024. 03. 25] 소켓과 웹소켓 (0) | 2024.03.25 |


