심화 팀 프로젝트인 sparta_news의 기본기능 구현이 끝났다
심화기능에서는 개인적으로 "검색기능"과 "게시물 전체조회시에 point개념을 도입해서 이를 통해 sort"하는 부분을 맡게 되었다.
TIL에서는 후자를 만들어보면서 겪은 오류와 그 해결과정을 정리해보려고 한다.
기본적으로 만들어볼 point는 게시물의 생성일, 댓글수, 좋아요를 종합하여 집계되는 개념으로 기획하였다.
구체적으로는 게시물의 생성일이 하루씩 지날 때마다 -5포인트되고, 댓글수만큼 +3점되며, 좋아요 1개당 +1점으로 계산하여 total_point를 계산한다. 그리고 이를 통해 "내림차순"으로 게시물을 정렬해볼 것이다.
즉, 최신이고 댓글과 좋아요가 많을수록 메인 페이지(전체 게시물 조회)의 상단에 노출되게 하는 것이다.
단, 최신 게시물인지와 댓글, 좋아요 각각의 계산에서의 가중치는 다르다 (-> -5, +3, +1)
최초에 작성한 코드는 다음과 같다
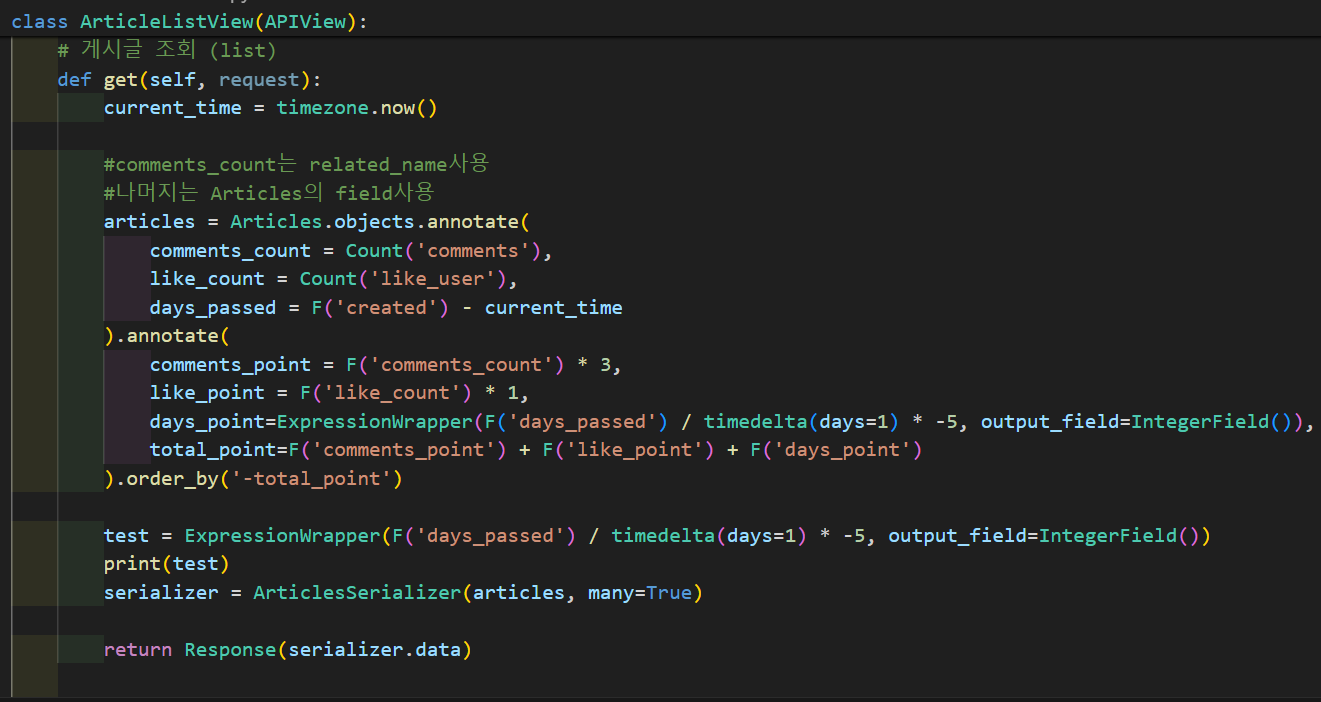
Django의 Queryset API 중 annotate를 사용하여 코드를 작성했다
annotate() 는 데이터베이스 집계 함수(ex. Count, Sum, Avg, Max, Min 등)를 적용하여 각 객체에 새로운 필드를 추가한다. 즉, 주로 그룹화된 데이터를 처리하고 집계된 값을 포함하는 새로운 필드를 만들 때 사용할 수 있다
이번에는 annotate를 내가 custom으로 만들어본 "total_point"라는 새로운 필드를 각 객체에 추가하여, 이를 통해 각 객체인 게시물들을 sorting해보기 위해 사용했다
fk인 필드를 annotate로 Count하기


annotate로 like_user를 Count하고, created의 필드값을 가져와서 계산하는 것은 Articles모델 테이블에서 바로 가능하다.
하지만 comments에 대한 정보는 Articles테이블에 없고, Comments모델 테이블에만 존재한다.
즉, comments에 대해서는 정참조로 접근할 수는 없고, Comments테이블의 related_name(역참조 매니저)를 통해 접근해야 한다.
기본적으로 articles라는 변수에 Articles모델로부터 annotate로 객체를 조회해온다. 그러므로 like_count와 days_passed는 Articles의 필드를 가져와서 바로 사용할 수 있고, comments_count는 역참조를 통해 Comments모델로부터 필드값을 가져와서 사용하는 것이다.
따라서 get()에서 comments_count = Count("comments")의 괄호 안의 "comments"는 역참조 매니저(related_name)인 "comment"이다.
days_passed와 days_point
최초 작성 코드를 postman으로 확인해본 결과, comments_point와 like_point는 정렬에 정상적으로 잘 반영되었다.
하지만 days_point는 shell_plus로 터미널상에서 몇몇 게시물의 created를 수정해서 확인해본 결과, days_point인 음수값이 커져서 total_point가 작아진 게시물들이 아래로 가는 게 아니라, 오히려 가장 상단으로 정렬되어 노출되는 오류를 발견했다. (현경님과 화면공유하면서 수정된 기능들을 체크해보다가 발견한 오류..)
print문을 코드 중간마다 찍어보면서 data는 잘 넘어오고 있는지 확인해보았는데,
days_passed 변수에 담긴 data가 제대로 계산(집계)되지 않은 것일 수 있다는 피드백을 얻었다
F객체와 timezone.now()를 사용하는 것이 서로 다른 자료형이므로 여기도 ExpressionWrapper를 사용해보니 문제가 해결되었다. postman확인 결과도 이제는 created가 이른 게시물이 아래로 잘 내려가서 조회되었다.

하지만 print문으로 종전의 (지금은 주석 처리된) days_passed와 ExpressionWrapper를 사용한 days_passed 두 개를 찍어본 결과, 넘어오는 데이터 자체에는 별다른 차이가 없는것 같은데 왜 오류 해결이 되었는지는 정확히 모르겠다..
그러나 효율성 면에서는 확실히 ExpressionWrapper를 사용하는 게 좋은 듯하다 (gpt에게 두 방법의 차이를 물어봤다)
왜냐하면 전자(current_time - F('created'))는 일반적인 파이썬 연산을 사용하는 경우이므로, 메모리 내의 파이썬에서 계산된다. 즉, DB에서 필드값을 가져와서 파이썬에서 직접 연산을 수행하는 방식이다.
따라서 코드가 간단하고 직관적이지만, DB의 성능 저하가 있을 수 있으며, 특히 대규모 데이터셋에서는 성능 저하가 있을 수 있다고 한다.
반면 ExpressionWrapper를 사용한 후자는 current_time - F('created')라는 SQL 표현식을 IntegerField()로 캐스팅하여 days_passed 필드에 저장하고 있다.
즉, SQL식을 직접 사용한 것이므로 쿼리 최적화와 더불어 계산 자체를 파이썬 자체가 아니라 DB에서 수행하므로 성능상 이점이 있을 수 있다고 한다.
Shell로 게시물의 created 수정하기
python manage.py shell_plus (->extension install 필요) # from datetime import datetime from datetie import timedelta article = Articels.objects.get(id=1) five_ago = timezone.now() - timedelta(days=5) article.created = five_ago article.save()
'TIL' 카테고리의 다른 글
| [TIL 2024. 05. 10] 심화 프로젝트 피드백 정리 (0) | 2024.05.13 |
|---|---|
| [TIL 2024. 05. 09] API문서 작성 (w. Notion) (0) | 2024.05.10 |
| [TIL 2024. 05. 07] 멀티스레딩과 멀티프로세싱 (0) | 2024.05.08 |
| [TIL 2024. 05. 03] 심화 팀프로젝트 (0) | 2024.05.07 |
| [TIL 2024. 05. 02] 웹 서버 | 웹 애플리케이션 서버 (0) | 2024.05.03 |

